公開日:2026年5月8日
はじめに
ComfyUIは、画像生成の流れを「ノード」と呼ばれるパーツで組み立てて使うツールです。
最初に画面を見ると、四角いボックスや線が並んでいて少し複雑に見えるかもしれません。ただ、基本の流れに沿って進めれば、最初の1枚を生成するところまではそこまで難しくありません。
この記事では、Windows向けのPortable版を使って、ComfyUIを導入し、公式のText to Image Workflowを読み込み、画像を生成するところまでを順番にまとめます。
今回は、ComfyUI公式ドキュメントで紹介されている流れに沿って進めます。モデルについても、公式ページで案内されているSD1.5モデルを使って、まずは基本の動作確認をしていきます。
この記事でわかること
1. ComfyUI Portable版をダウンロードする
まずは、ComfyUIのPortable版をダウンロードします。
Portable版は、ComfyUI本体と実行に必要な環境がまとまっているWindows向けの形式です。最初にComfyUIを試す場合は、このPortable版を使うと進めやすいです。
ダウンロードは、ComfyUI公式ドキュメントのPortable版ページから行います。
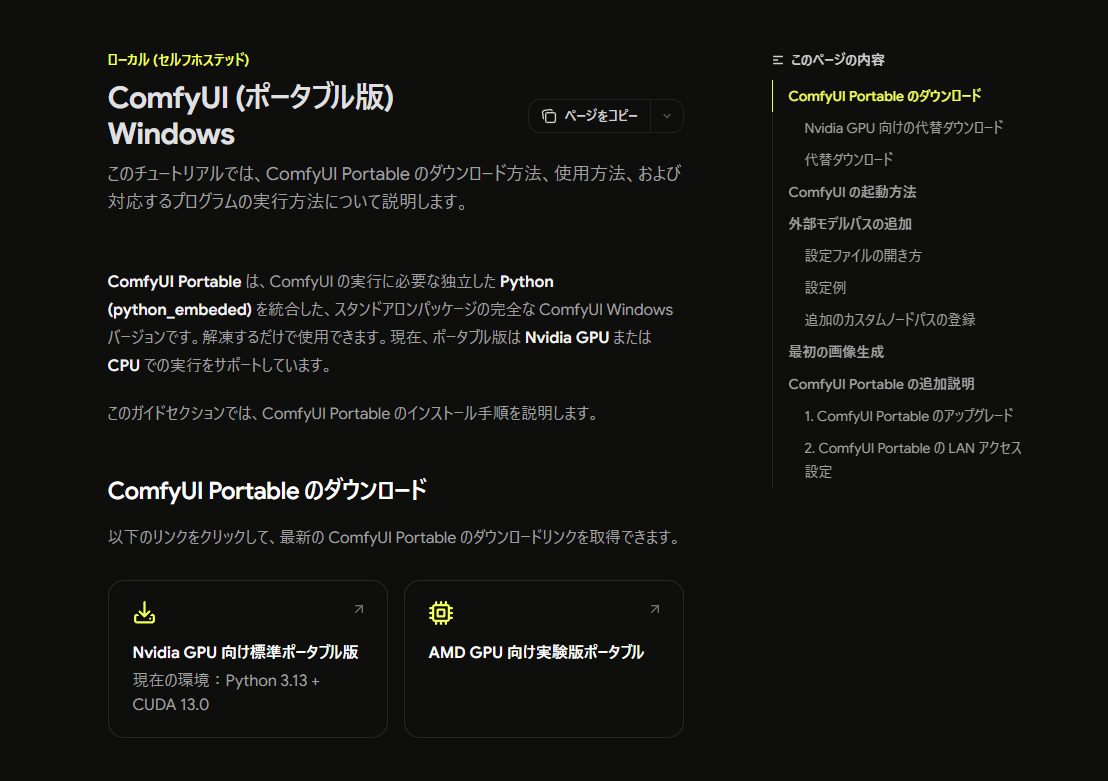
ページ内の「ComfyUI Portable のダウンロード」から、使用している環境に合ったものを選びます。
NVIDIAのGPUを使う場合は、「Nvidia GPU 向け標準ポータブル版」を選びます。
2. ダウンロードしたファイルを展開する
ダウンロードした圧縮ファイルを、任意の場所に展開します。
たとえば、以下のような場所に置くと管理しやすいです。
D:\ComfyUI_windows_portable\フォルダ名や保存場所は自由ですが、あとから見つけやすい場所にしておくと安心です。
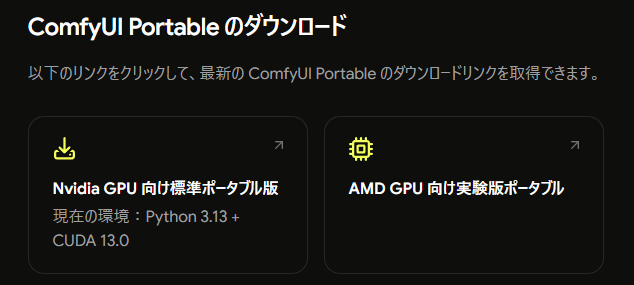
展開したフォルダの中には、ComfyUI、python_embeded、run_nvidia_gpu.bat などのファイルやフォルダが入っています。
NVIDIAのGPUを使う場合は、基本の起動用として run_nvidia_gpu.bat を使います。
3. 公式Text to Image Workflowを確認する
ComfyUIで画像を生成するには、ComfyUI本体とは別に、画像生成に使うモデルファイルが必要です。
最初は「どのモデルを使えばいいの?」と迷いやすいところですが、今回はComfyUI公式ドキュメントの Text to Image Workflowに沿って進めます。
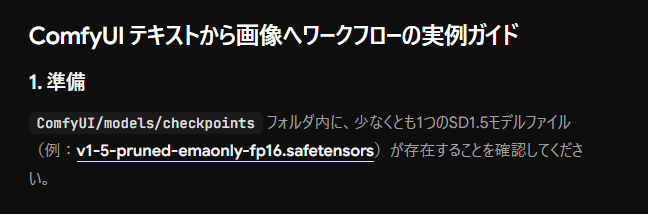
公式ページでは、ComfyUI/models/checkpoints フォルダ内に、少なくとも1つのSD1.5モデルファイルを入れておくよう案内されています。
例として紹介されているのが、v1-5-pruned-emaonly-fp16.safetensors です。
4. 公式案内に沿ってSD1.5モデルをダウンロードする
公式Text to Image Workflowのページ内には、SD1.5モデルファイルの例として v1-5-pruned-emaonly-fp16.safetensors が紹介されています。
今回は、この公式案内に沿ってモデルを用意します。
流れは次のようになります。
- ComfyUI公式 Text to Image Workflow のページを開く
v1-5-pruned-emaonly-fp16.safetensorsのリンクをクリックする- リンク先のHugging Faceページで download を押す
- ダウンロードが完了したら、モデルファイルをComfyUIの checkpoints フォルダに入れる
モデルファイルはサイズが大きいため、ダウンロードに時間がかかる場合があります。
また、モデルごとに配布条件や利用範囲が異なることがあります。ダウンロードする際は、配布元の説明やライセンスもあわせて確認してください。
5. モデルファイルをcheckpointsフォルダに入れる
ダウンロードした v1-5-pruned-emaonly-fp16.safetensors を、ComfyUIの checkpoints フォルダに入れます。
保存先は次の場所です。
ComfyUI\models\checkpointsPortable版を D:\ComfyUI_windows_portable\ に展開した場合は、次のような場所になります。
D:\ComfyUI_windows_portable\ComfyUI\models\checkpointsこのフォルダにモデルファイルを入れておくと、あとでComfyUI内の「チェックポイントを読み込む」ノードから選べるようになります。
すでにComfyUIを起動している場合は、モデル追加後に再起動しておくと安心です。
6. ComfyUIを起動する
モデルファイルを配置したら、ComfyUIを起動します。
NVIDIAのGPUを使う場合は、Portable版フォルダ内の以下のファイルをダブルクリックします。
run_nvidia_gpu.bat起動すると、黒いコンソール画面が表示されます。しばらく待つと、ブラウザでComfyUIの画面が開きます。
ブラウザが自動で開かない場合は、黒い画面に表示されているURLを確認します。多くの場合は、以下のようなURLです。
http://127.0.0.1:8188/7. ComfyUIの表示を日本語にする
この記事では、日本語表示のComfyUI画面をもとに説明します。
ComfyUIが英語で表示されている場合は、画面左下の歯車マークを開き、表示言語を日本語に変更します。
日本語化すると、ノード名やボタン名が日本語で表示されます。この記事内の説明も、日本語表示に合わせて進めます。
たとえば、英語表示では Load Checkpoint と表示される部分は、日本語表示では「チェックポイントを読み込む」と表示されます。
8. 公式ワークフロー画像を読み込む
今回は、ComfyUI公式ドキュメントで紹介されている基本的なText to Image Workflowを使って生成していきます。
公式ページにはワークフロー画像が用意されています。この画像をComfyUIの画面にドラッグ&ドロップすると、同じワークフローを読み込めます。
また、公式ページ内の補足にもあるように、メニューの Workflows → Open から読み込むこともできます。
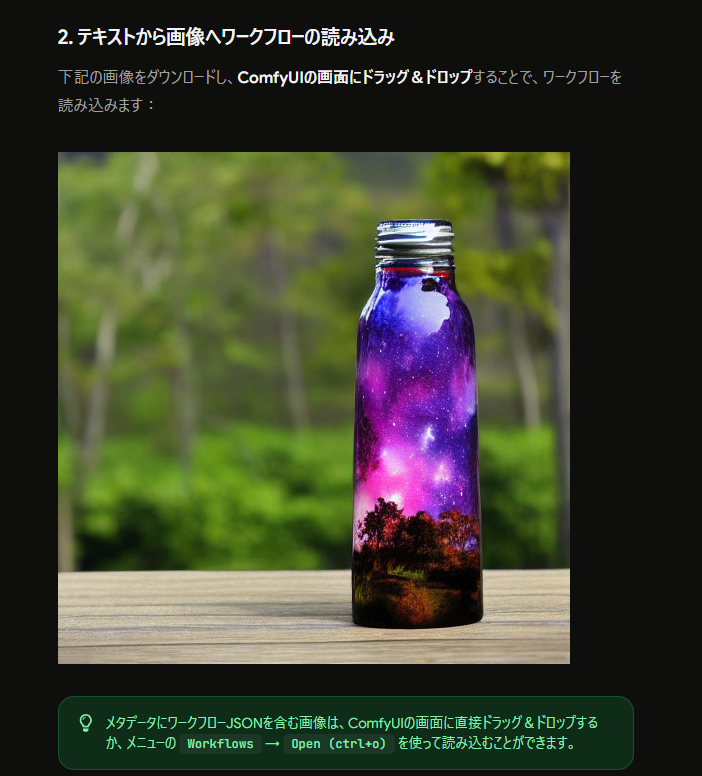
ワークフローを読み込むと、ComfyUIの画面上に複数のノードが表示されます。
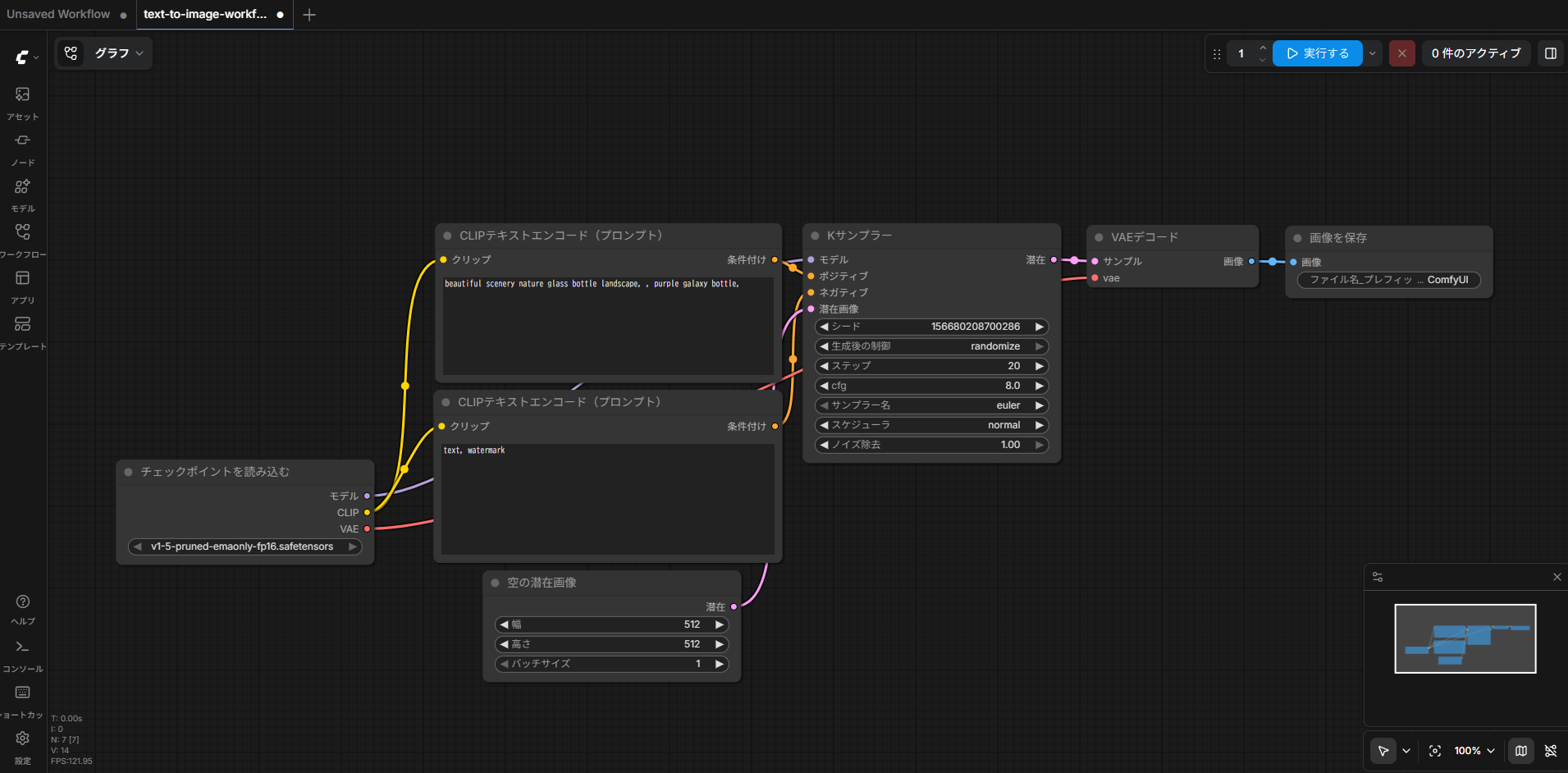
このワークフローには、モデルの読み込み、プロンプト入力、画像生成、保存までの基本的な流れが含まれています。
9. まずは公式ワークフローのプロンプトで生成してみる
ワークフローを読み込んだら、最初は中身を大きく変えずに、そのまま生成してみます。
まず、「チェックポイントを読み込む」ノードで、先ほど用意したSD1.5モデルが選択されていることを確認します。
モデルが選択できていることを確認したら、画面右上の 実行する を押します。
生成が終わると、「画像を保存」ノードの中に生成結果が表示されます。
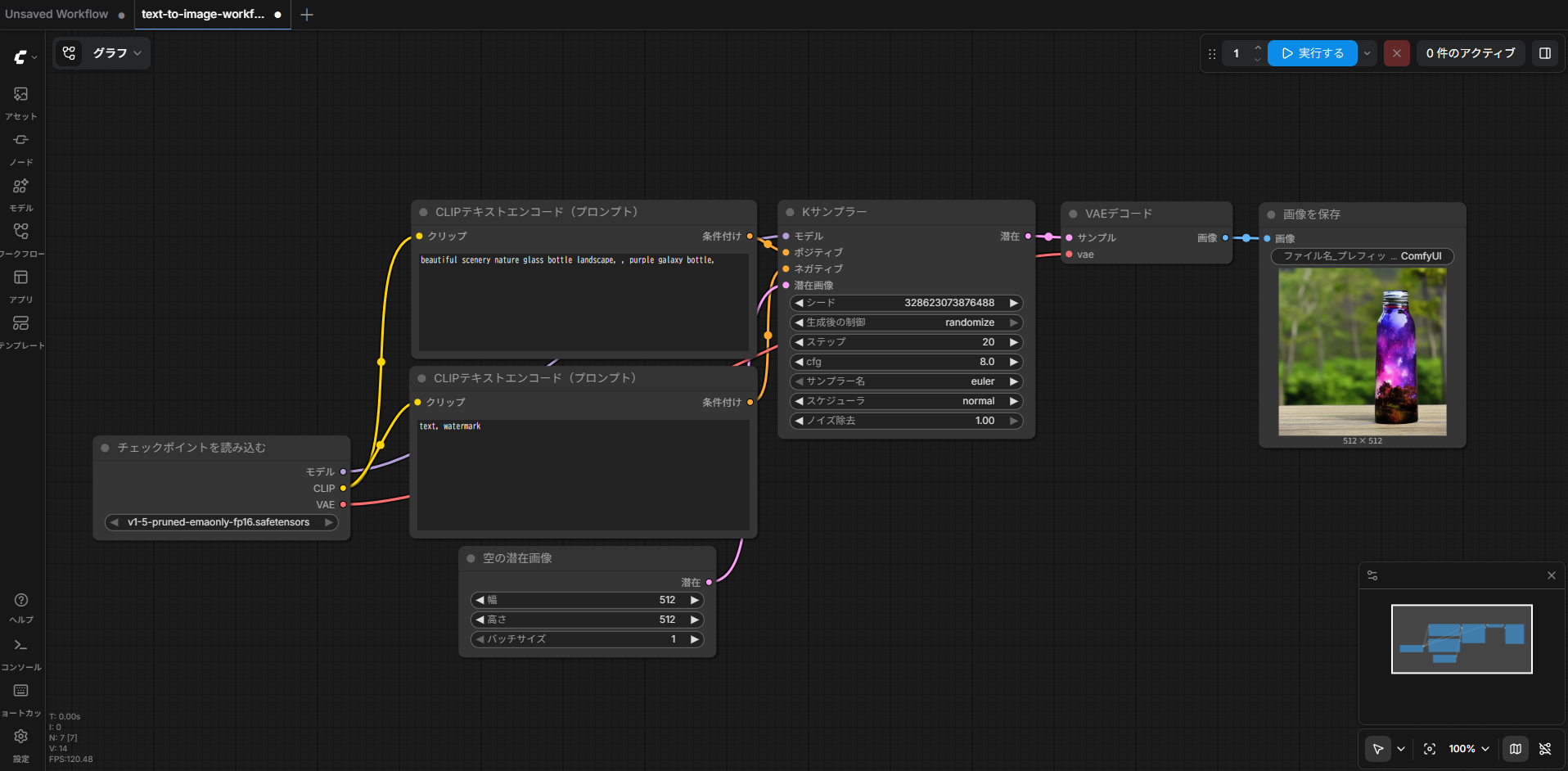
ここまでできれば、ComfyUIの基本的な動作確認はできています。
10. テキストプロンプトを自分で書き換えてみる
公式ワークフローのまま生成できたら、次にプロンプトを書き換えてみます。
ワークフロー内には、CLIP テキスト エンコード(プロンプト)というノードが2つあります。
上にある入力欄が、生成したい内容を書くポジティブプロンプトです。下にある入力欄が、避けたい内容を書くネガティブプロンプトです。
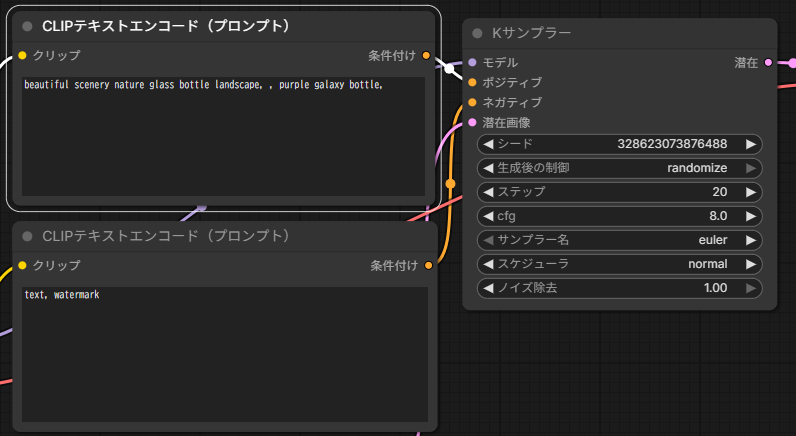
ポジティブプロンプトには、生成したい内容を書きます。最初は短い内容で十分です。
1girl, portrait, smileネガティブプロンプトには、避けたい要素を書きます。
low quality, bad anatomy, blurry書き換えると、次のようになります。
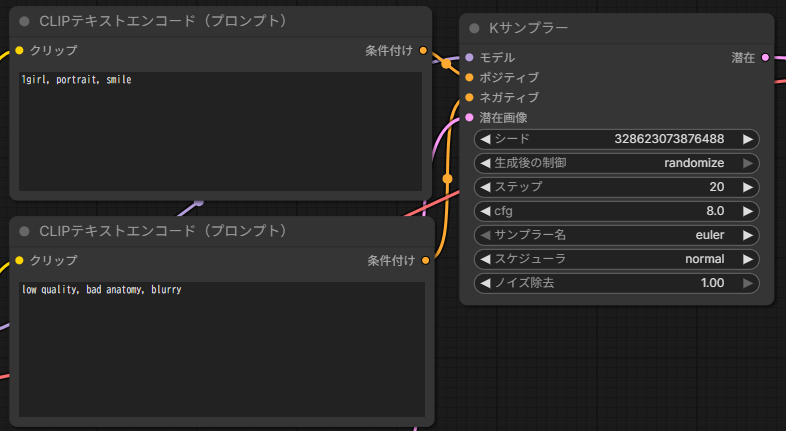
書き換えたら、もう一度 実行する を押して生成します。テキストを変えることで、生成される画像の内容が変わることを確認できます。
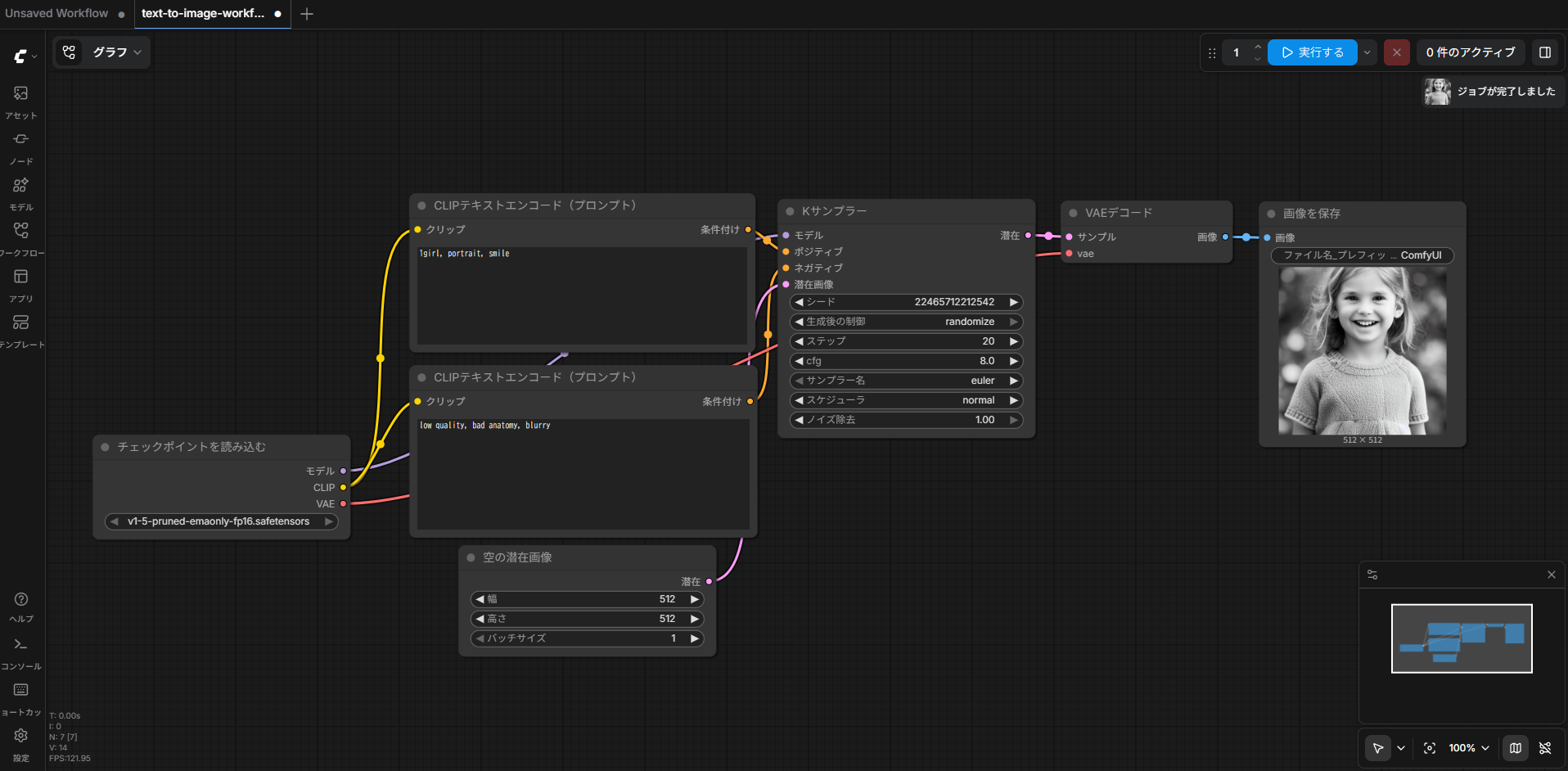
11. 生成された画像を確認する
生成された画像はComfyUIの画面上で確認でき、左側の アセット をクリックすると一覧が表示されます。
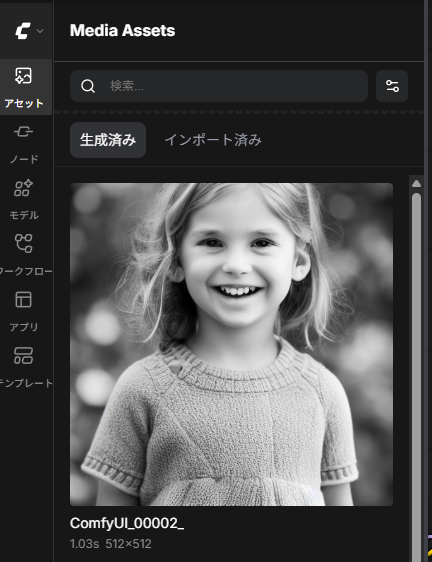
また、通常はComfyUIフォルダ内の output フォルダにも保存されます。
ComfyUI\output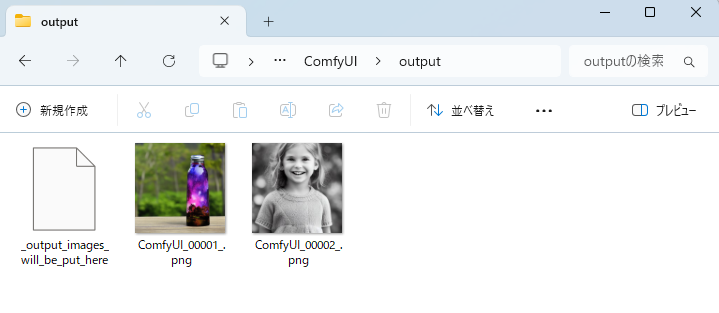
ComfyUI上で画像が表示され、output フォルダにも保存されていれば、最初の画像生成は成功です。
12. うまく動かないときの確認
ComfyUIが起動しない、モデルが選べない、画像が生成されない場合は、まず以下を確認します。
- 黒いコンソール画面に赤いエラーが出ていないか
- モデルファイルを checkpoints フォルダに入れているか
- モデルファイルの拡張子が
.safetensorsまたは.ckptになっているか - モデル配置後にComfyUIを再起動したか
- フォルダパスが複雑すぎないか
- GPUのVRAMが不足していないか
特に、モデルファイルの置き場所はつまずきやすいポイントです。ComfyUI\models\checkpoints に入っているかをもう一度確認してみてください。
また、ComfyUIが動いている間は、起動時に開いた黒いコンソール画面を閉じないようにします。閉じてしまった場合は、もう一度 run_nvidia_gpu.bat から起動し直します。
まとめ
この記事では、ComfyUI Portable版を使って、導入から最初の画像生成までの流れをまとめました。
流れを整理すると、次のようになります。
- ComfyUI Portable版をダウンロードする
- ファイルを展開する
- 公式Text to Image Workflowを確認する
- 公式案内に沿ってSD1.5モデルをダウンロードする
- モデルを checkpoints フォルダに入れる
- ComfyUIを起動する
- 表示言語を日本語にする
- 公式ワークフロー画像を読み込む
- まず公式の状態で生成する
- プロンプトを書き換えてもう一度生成する
- 生成結果を確認する
最初は画面が複雑に見えますが、基本の流れはそこまで多くありません。まずは公式の流れに沿って、1枚生成できるところまで進めてみてください。
SDXLやPony系などのモデルもComfyUIで使えますが、推奨設定やプロンプトの考え方が変わる部分があります。そのあたりは、別の記事で整理していく予定です。